NetIQ secures organizations through a comprehensive set of identity and access services for workforce and customer identities.
Take advantage of automated provisioning for all of your identity stores.
Match authentication strength and authorization level to the measured risk at hand.
Benefit from increased security and usability through synergistic integrations.
Deliver the right access to the right resources with the least amount of friction possible.
Use a platform that offers purpose-based controls for customers engaging with your services and resources.
Make consumer interaction more engaging and convenient with low-friction access.
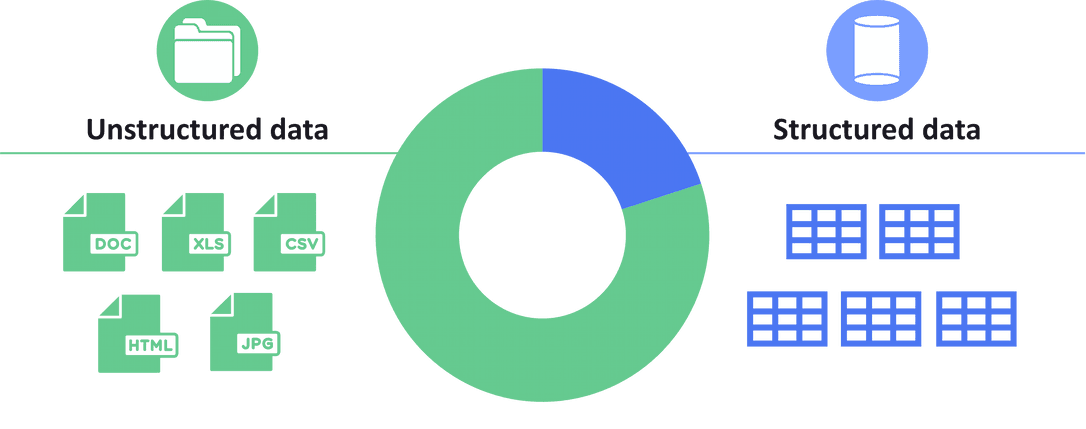
Manage and automate governance tasks to optimize, secure, and protect your unstructured data.
Drive least privilege across your platform for administrative accounts by applying policies based on identity attributes.
Deliver simplified, secure access to the right users, regardless of the device type or location, and minimize risk to the organization.
Govern access to resources, adapt to risk, and improve business agility with a comprehensive IGA platform.
Gain visibility and control of privileged user activities to deliver actionable security intelligence and quickly address evolving threats.
Centralize delegation and administration of policy controls across your hybrid IT environment.
Gain the same level of control over unstructured data as you have with services by extending your identity governance to documents and files.
Deliver simplified, secure access to the right users, regardless of the device type or location, and minimize risk to the organization.
Govern access to resources, adapt to risk, and improve business agility with a comprehensive IGA platform.
Gain visibility and control of privileged user activities to deliver actionable security intelligence and quickly address evolving threats.
Centralize delegation and administration of policy controls across your hybrid IT environment.
Gain the same level of control over unstructured data as you have with services by extending your identity governance to documents and files.
Martin Oldin
Architecture Team Leader
Brad Abbott
Sr. Manager, IT Risk, IAM
Annie Kionga
Identity Product Owner